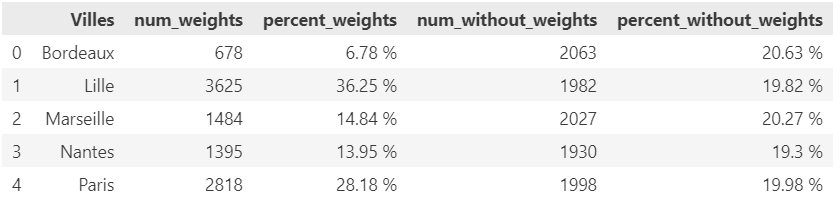
S’il est bien une pratique importante dans le traitement des données, c’est d’uniformiser la data afin de rendre le traitement le plus simple et efficace possible.
Lors d’un projet d’analyse sociale du territoire français, j’ai été confronté à la problématique des accents et gestions des ‘-‘ ou des espaces sur les départements et régions.
Pour gagner en temps et efficacité, j’ai trouvé une solution extrêmement efficace, la librairie python « UNIDECODE« . je vous livre ici le Tips
Bien entendu, j’ai créé un dataframe en intégrant de manière volontaire des données avec accents pour la démo.
You might also like


Injecter du html dans votre rapport Power BI
juin 10, 2024