Cher (chère) lecteur/lectrice,
Dans les méandres de mes projets personnels et étant un grand mélomane, je me suis donné comme objectif de créer ma propre base de données basée sur les titres les plus écoutés entre les débuts des DATAs de Spotify jusqu’en 2024(mai).
Aimant aller jusqu’au bout de mes idées, j’ai entrepris de « web-scrapper » (grâce à la superbe librairie python : ‘Helium’) les paroles en anglais et en français de ces titres (scrapper l’ensemble étant très lourd c’est déjà pas mal !)
LIEN EN BAS DE L’ARTICLE !
Une fois la structure configurée sur Workbench, les données importées via des fichiers csv, m’est venue l’idée de partager mon fichier qui représente un très bon exercice pour travailler les compétences en SQL.
En effet, le fichier Dump comprend 4 tables au travers desquelles de multiples manipulations sont possibles afin de travailler :
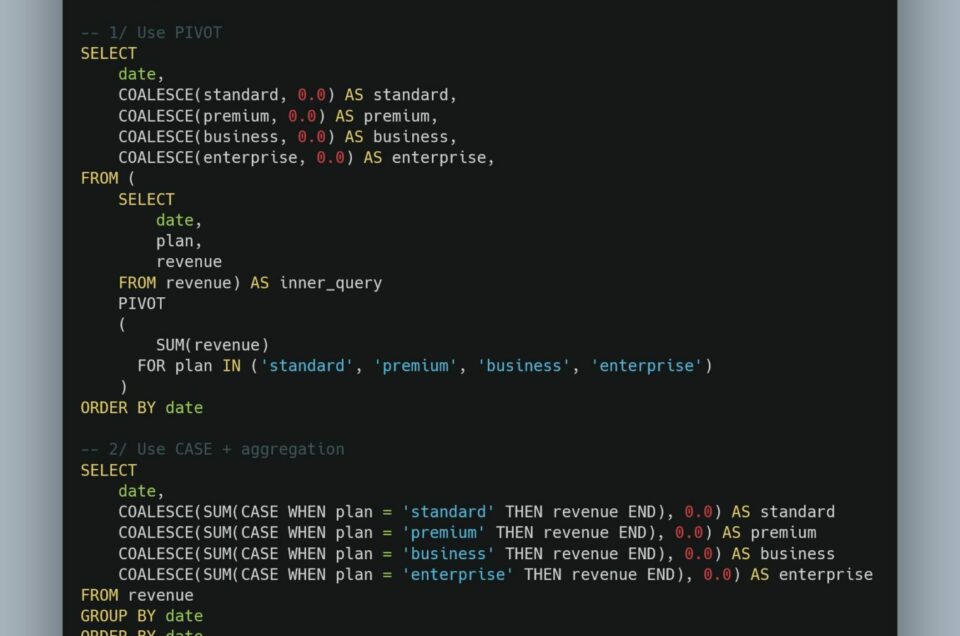
- les CTE (Common Table Expression),
- les WINDOWS FUNCTIONS,
- les filtres de base,
- les systèmes de recommandations basés sur le KNN (K-Nearest Neighbour) ainsi que le clustering via la table « audio_features »,
- le clustering
- les fonctions avancées LAG(), DENSE_RANK()…
Bref, une cour de récréation pour Data Analyst en devenir ou souhaitant s’amuser avec des données.
En résumé, la base de données comprends 4 tables :
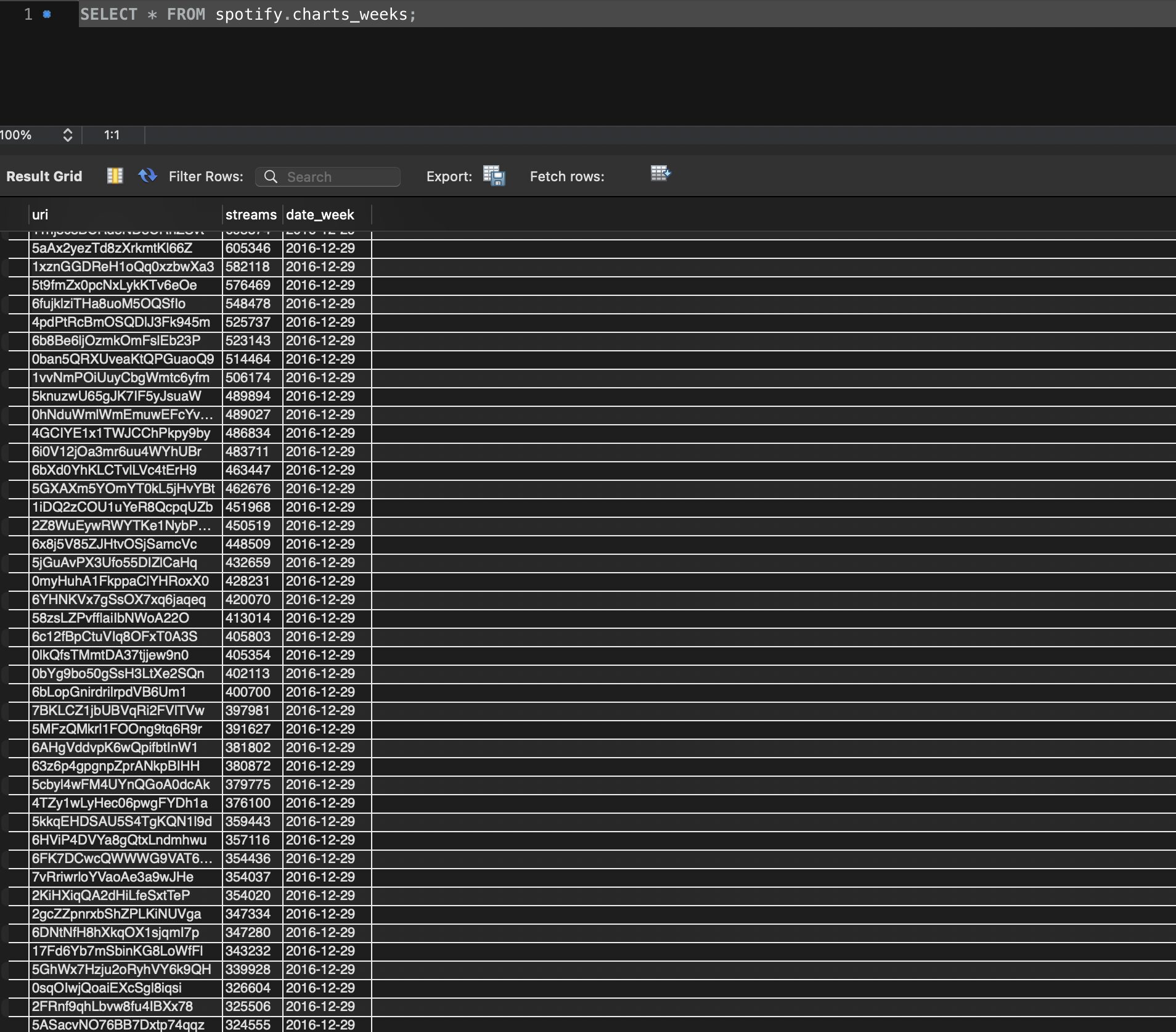
- « charts_weeks » :
- uri (id du morceau musical) FK,
- streams (nombre de streamings sur la semaine),
- date_week (date de la semaine concernée);
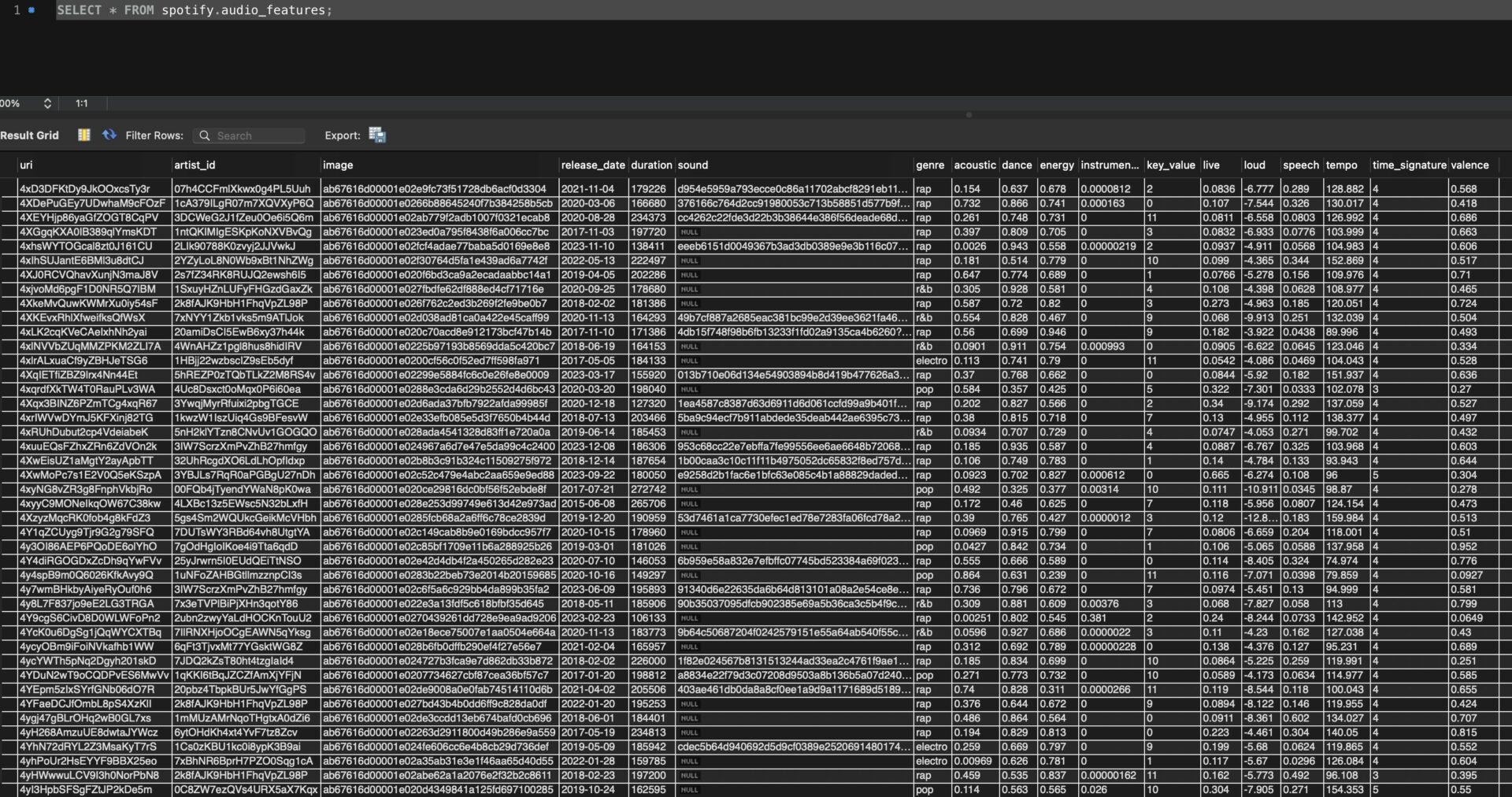
- « audio_features » :
- uri (id du morceau musical) FK,
- artist_id,
- image (image de l’album),
- release_date (date de sortie officielle),
- duration (en millisecondes)
- sound (extrait audio),
- genre (préalablement préparé pour générer des genres globaux),
- acoustic,
- danceability,
- energy,
- instrumental,
- key_value,
- live,
- loud,
- speech,
- tempo,
- time_signature,
- valence
- (les données quantitatives provenant de spotify sont diponibles ici : infos_quantitative_spotify )
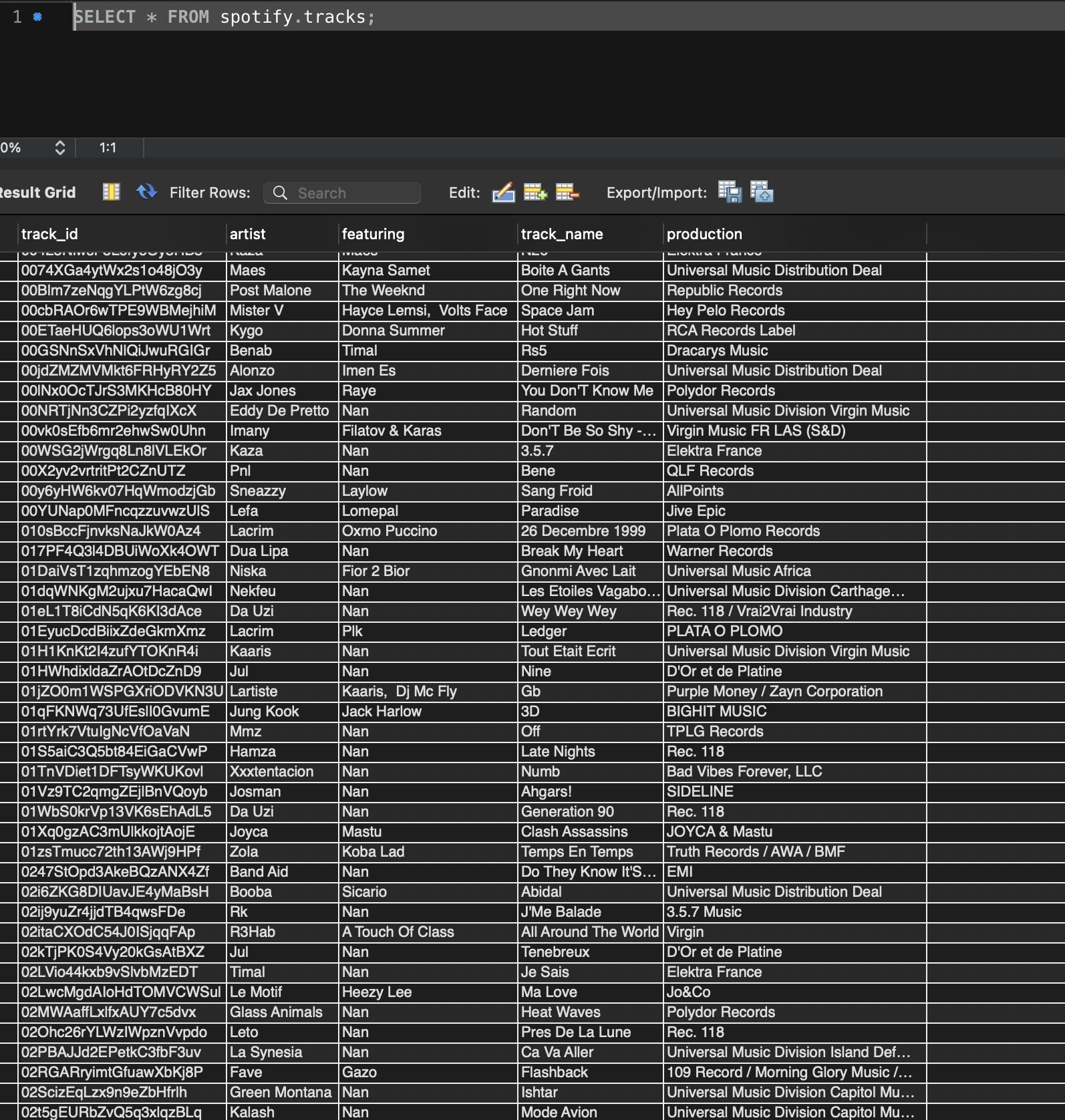
- « tracks » :
- track_id,
- artist (artiste principal)
- featuring (Null si aucun featuring)
- track_name,
- production
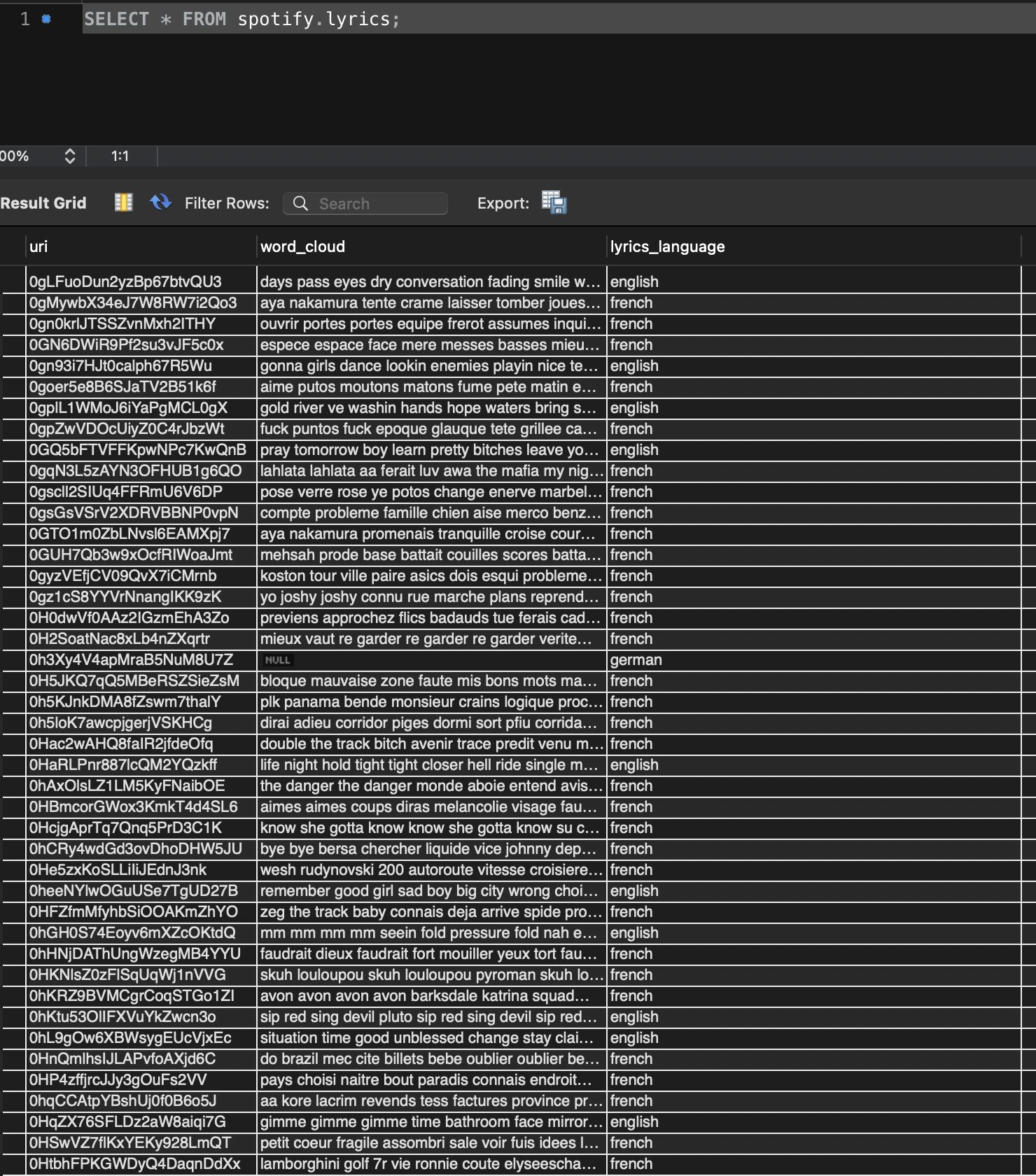
- « lyrics »:
- uri (id du morceau musical) PRIMARY KEY,
- word_cloud (paroles filtrées : les pronoms, déterminants, etc ont été enlevés, dans la mesure du réalisable),
- lyrics_language (langue de la chanson)
Infos supplémentaires :
Taille de la BDD : 28.5 mib
Characterset : utf8mb4
Télécharger le fichier DUMP SQL :
Télécharger le fichier DUMP
You might also like