Le « scraping » ou l’art de récupérer des informations via les balises html de n’importe quel site internet est sujet à discussion… Droit intellectuel, violation des conditions d’utilisation (se référer aux CU du site en question), charges sur le serveur, etc…
Si autant de questions se posent, il ne faut pas non plus se voiler la face, le scraping est énormément utilisé : veille concurrentielle (‘benchmarking’), génération de leads (prospection), surveillance de réputation en ligne, analyse de marché et j’en passe.
En tant que Data Analyst, le scraping est une technique importante à connaître, et il faut bien se faire la main sur des sites. Si l’on pense éthique, on peut penser donc que scraper des sites internets tels que ceux des GAFAs est un bon moyen de travailler les compétences. Les moyens financiers sont tels qu’un internaute seul ne va pas à lui seul causer de problèmes, tant que les données collectées sont utilisées à des fins personnelles (pour ma part des compétences techniques).
Ainsi, j’ai décidé de tenter de collecter des données sur les produits disponibles sur une grande plateforme…
Le stratégie est la suivante :
- trouver la liste des catégories de produits,
- à chaque lien de catégorie, scraper la liste des liens des produits dépendant de cette dernière,
- et enfin scraper sur le lien de la page article.
Les problèmes techniques rencontrés sont quant à eux nombreux :
- blocage systématique sur les requêtes intempestives,
- liens encodés à remanier avec des .replace(« ; », »& »)
- gérer le header de requête…
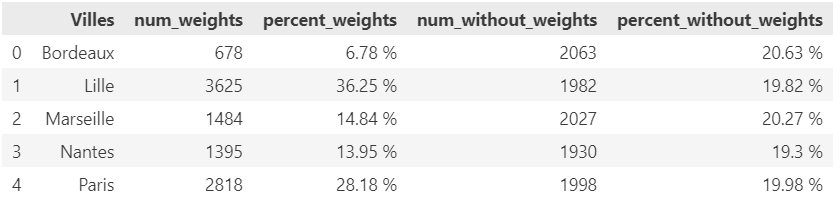
Avec de la réflexion et des tests, j’ai été en mesure de récolter plus de 8000 articles avec leurs caractéristiques.
Ainsi, avec les librairies pandas, requests, BeautifulSoup, du regex, le tout sous python, voici la logique que j’ai codée.
Import de librairies nécessaires :
création du header grâce à l’inspecteur sous firefox :
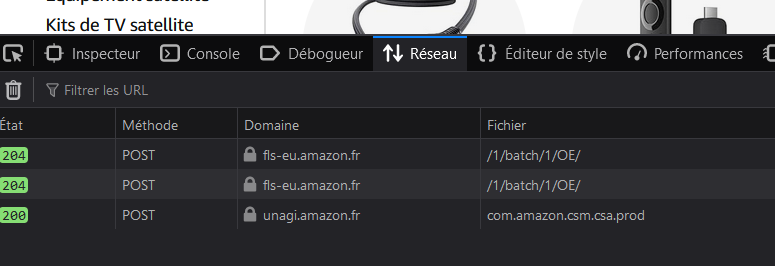
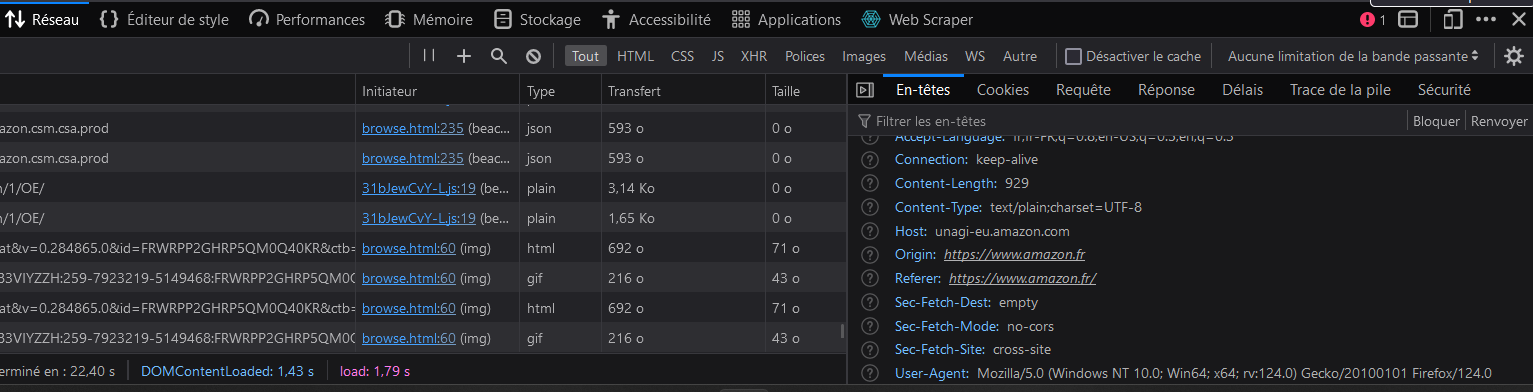
n’oubliez-pas de rafraîchir la page (ctrl + r) afin que les données se mettent à jour. Vous observerez alors le ‘User-agent’ indiqué par votre navigateur sur le site d’amazon.
Dans le code suivant :
- Création des listes vides qui vont stocker les informations souhaitées,
- Initialisation d’un compteur à Zéro afin de visionner les occurrences (et ainsi surveiller le fonctionnement de chaque itération),
- Requête sur l’url grâce à la librairie « requests » et paramètre du header réglé,
- lancement du script à la condition que la réponse à la requête soit « 200 »
- condition « while » pour indiquer que si le scraping du nom de l’article est vide, le script relance la requête sur la même url
- un time.sleep() pour conditionner un comportement humain de navigation sur internet
Puis enfin :
- on vient collecter chaque information souhaitée,
- chaque information est stockée dans une liste dédiée,
- puis on crée un dataframe pandas en vue de l’exporter…
Grâce aux librairies et langage Python, via un notebook google colaboratory, j’ai pu collecter plusieurs milliers de produits et informations correspondantes comme le prix, la marque, la note des acheteurs, le nombre d’avis, la couleur, la matière, etc…
You might also like