
Les doublons sont la première préoccupation des Data analysts. Ne pas les prendre en compte fausse les calculs et les insights.
Alors comment les détecter et les isoler en SQL en utilisant le moins de mémoire possible ?
Voici un exemple grâce au « QUALIFY » et « ROW_NUMBER »
You might also like

Base de données spotify charts france
septembre 13, 2024
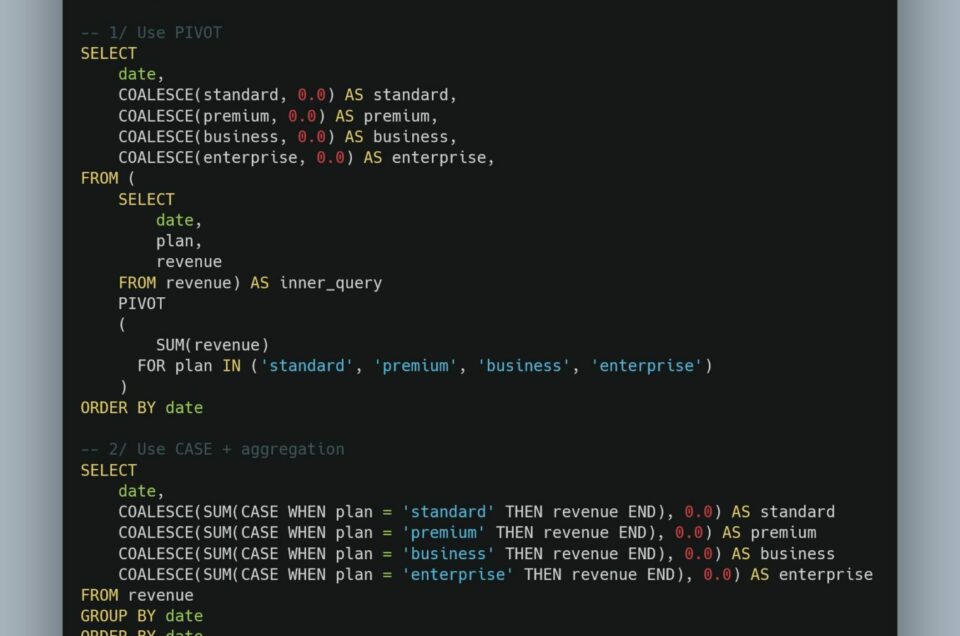
SQL : comment créer un tableau croisé sans galère ?
juin 25, 2024